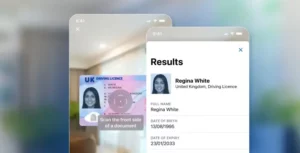
Extraction de texte
L’extraction de texte est le processus d’identification et d’extraction automatique d’informations pertinentes à partir de documents textuels non structurés, tels que des courriels, des pages web ou des rapports. Il s’agit d’analyser le texte et d’identifier des points de données spécifiques, tels que des noms, des adresses, des dates et des nombres, ainsi que d’extraire un contenu significatif, tel que des phrases ou des paragraphes.
L’extraction de texte fait généralement appel à des techniques de traitement du langage naturel (NLP), notamment l’étiquetage de la partie du discours, la reconnaissance des entités nommées et l’analyse syntaxique du texte. Ces techniques permettent au système d’identifier et de comprendre la structure et le contexte du texte, ce qui lui permet d’extraire avec précision les informations souhaitées.
L’extraction de texte a de nombreuses applications dans divers secteurs. Elle peut être utilisée pour des tâches telles que l’exploration de données, l’analyse des sentiments, la catégorisation du contenu et la recherche d’informations. En automatisant le processus d’extraction, les organisations peuvent gagner du temps et des ressources et obtenir des informations précieuses à partir de grands volumes de données textuelles.