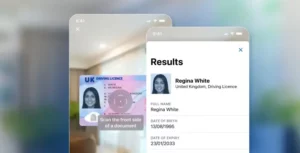
Text Extraction
Text extraction is the process of automatically identifying and extracting relevant information from unstructured text documents, such as emails, web pages, or reports. It involves analyzing the text and identifying specific data points, such as names, addresses, dates, and numbers, as well as extracting meaningful content, such as sentences or paragraphs.
Text extraction typically employs natural language processing (NLP) techniques, including part-of-speech tagging, named entity recognition, and text parsing. These techniques enable the system to identify and understand the structure and context of the text, allowing it to extract the desired information accurately.
Text extraction has numerous applications across various industries. It can be utilized for tasks like data mining, sentiment analysis, content categorization, and information retrieval. By automating the extraction process, organizations can save time and resources and gain valuable insights from large volumes of textual data.