Mercearias sob a ótica da IA: criando reconhecimento de produtos em tempo real

Escrito por: Ivan Relić, engenheiro líder de aprendizado de máquina
Em Microblink, aplicamos inteligência artificial a problemas do mundo real com o objetivo de facilitar a vida do maior número possível de pessoas. Recentemente, nossas equipes de ML têm procurado maneiras de usar a visão computacional para levar o melhor das compras on-line para os supermercados em todo o mundo. Queríamos permitir que os clientes interagissem com os produtos do supermercado a partir de seus smartphones para que pudessem ver rapidamente coisas como:
- Avaliações de produtos
- Ofertas de reembolso
- Informações sobre alergênicos e valores nutricionais
- Qualquer outra coisa que torne sua experiência de compra melhor!
Por outro lado, queríamos que fornecedores, varejistas e marcas de bens de consumo embalados (CPG) usassem essa tecnologia para realizar promoções direcionadas, orientar sua estratégia de preços e manter a loja funcionando sem problemas.

Não somos os primeiros a trabalhar nesse problema – o Google vem tentando ganhar terreno com uma solução semelhante – mas estávamos mais bem posicionados para enfrentá-lo com eficiência. Nosso produto Shopper Intelligence já captura dados de compras de recibos de varejo para que as marcas possam criar programas de fidelidade orientados por dados e os compradores possam lucrar com eles. Ao longo dos anos, processamos mais de 5 bilhões de compras exclusivas e criamos um catálogo abrangente de produtos de supermercado. Também criamos vários modelos de ML projetados para serem executados com eficiência em dispositivos móveis. Um desses modelos usados para detectar recibos também serviu como base para detectar produtos nas prateleiras.
Obtendo os dados
Além do nosso catálogo de produtos, tentamos usar vários conjuntos de dados de código aberto, como o SKU-110K, para obter dados de treinamento. Eles foram um bom ponto de partida para a coleta de dados, mas seu uso comercial é proibido. Como não tínhamos outra opção a não ser fazer as coisas por conta própria, nossa equipe foi às principais lojas de varejo em todo o país, capturando imagens de prateleiras de longe e imagens de produtos individuais. Também foi solicitado que tirassem uma foto do código de barras de cada produto, para que pudéssemos conectá-lo ao UPC (Unique Product Code) e obter um identificador confiável para nossa recuperação. Em apenas alguns meses, coletamos milhões de fotos de lojas de varejo em todo o país.

Em seguida, nossa equipe de anotação examinou todas essas imagens para tentar identificar os produtos que apareciam nelas. Temos uma equipe de 100 anotadores. Para acelerar o fluxo de trabalho, criamos um modelo inicial de pré-anotações que nos permitiu rotular milhões de embalagens de produtos e dezenas de milhares de imagens de prateleiras.
Agora estávamos prontos para começar a fazer o treinamento adequado do modelo.
Detecção de produtos de um fluxo de câmera
A primeira coisa que precisamos fazer é detectar produtos distintos enquanto eles estão nas prateleiras para que possam ser classificados por outros modelos posteriormente no processo. Nosso detector teve de ser executado em tempo real em dispositivos móveis para recortar imagens de produtos quando o usuário estiver examinando a prateleira de perto ou de longe.
O modelo que treinamos coloca caixas delimitadoras em torno de cada embalagem de produto individual. No futuro, poderemos mudar para a segmentação de polígonos, pois os bens de consumo tendem a ter todas as formas e tamanhos. Usamos um limite de interseção sobre união relativamente rigoroso de 0,7 e ainda conseguimos atingir uma pontuação f1 de 92%. Também reduzimos o tempo de inferência do modelo para menos de 100 ms no iPhone 8 e superior, graças ao nosso mecanismo de inferência interno.
O maior desafio para o nosso detector de produtos no momento é a perspectiva da imagem. Quando uma imagem é tirada de um ângulo, a embalagem de um produto pode acabar tendo uma forma completamente diferente e distorcida. Para resolver esse problema, adicionamos um modelo de detecção de prateleira à mistura. Podemos usar a prateleira como um ponto de referência para deformar rapidamente as imagens e aumentar nossas chances de fazer detecções precisas.

Diferenciando os produtos
Uma vez detectados, os produtos precisam ser classificados em suas respectivas classes. Quando dizemos classes, queremos dizer UPCs – e há MUITOS deles. Não apenas existem milhões de produtos de supermercado, mas as marcas adoram mudar suas embalagens sempre que têm vontade. Definitivamente, esse não é um problema de classificação comum.
O grande número de classes em potencial nos levou a tentar uma abordagem diferente, usando um sistema de incorporação e recuperação. A ideia é simples: converter cada cultura de produto em um vetor de recursos e, em seguida, recuperar vetores semelhantes do banco de dados. A representação condensada de imagens de produtos pode ser comparada muito mais rapidamente e não é sensível a alterações no brilho e no ângulo de escaneamento.
Atualmente, temos cerca de um milhão de produtos indexados que são armazenados e consultados em relação às incorporações de entrada usando um algoritmo k-NN, com o valor de saída para cada par variando de -1 a 1. Quanto mais próximo de 1 for o produto escalar, mais semelhantes serão os produtos. No nosso caso, a maioria das recuperações acima de 0,75 foi considerada correta, mas esse limite deverá aumentar à medida que continuarmos a expandir nosso índice.
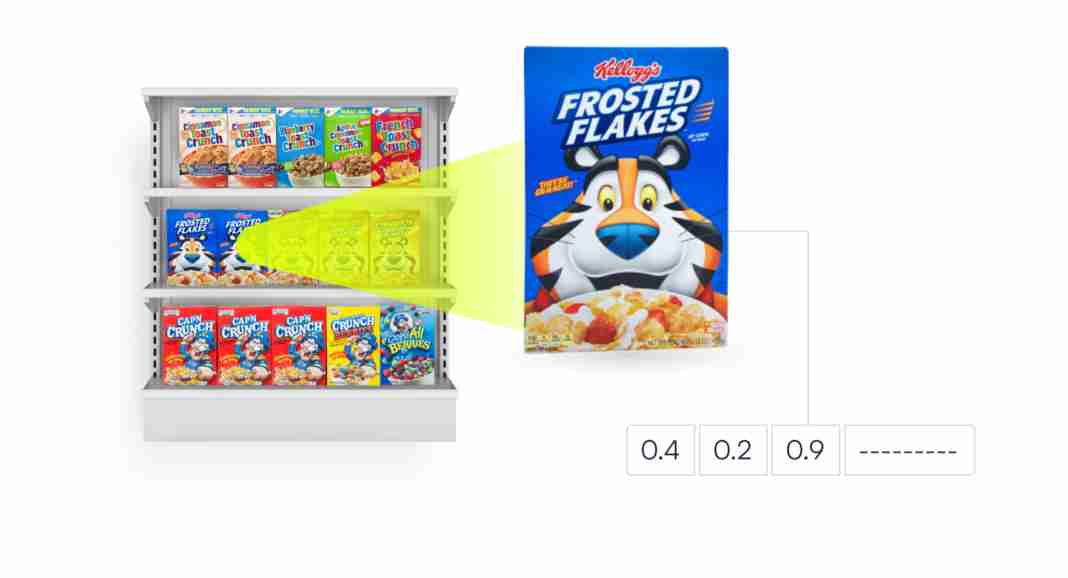
Fizemos experiências com várias arquiteturas de modelos para chegar à configuração que funciona melhor. Queríamos que o modelo recuperasse os k vetores mais semelhantes quando recebesse uma nova imagem inédita de um produto. Mas isso se torna um verdadeiro desafio com diferenças finas, como tamanhos e sabores de embalagens, que às vezes são difíceis de distinguir até mesmo para os seres humanos.

Nosso objetivo era otimizar a taxa de acerto no primeiro resultado de recuperação, obter o máximo de recall e fazer com que um modelo generalizasse bem os produtos que não havia visto durante o treinamento. A taxa de acerto na primeira recuperação significa que, depois que criamos o vetor de incorporação e o usamos para recuperar, digamos, cem vizinhos mais próximos do banco de dados, o vetor mais próximo é realmente o produto correto. No entanto, esse é o cenário perfeito, e o incorporador ainda pode ter dificuldades para diferenciar as pequenas variações do produto. É por isso que é importante ter uma forte recuperação para que nossos métodos de reclassificação tenham mais chances de escolher o verdadeiro vencedor, caso ele não seja o primeiro.
Nosso melhor modelo atual tem uma taxa de acerto de 93% no primeiro resultado em exemplos de produtos não vistos. A taxa de acerto nos 10 vizinhos mais próximos é de 98%, o que significa que a reclassificação deve produzir resultados precisos na maioria dos casos.
Assim como o detector, esse modelo precisa ser executado em tempo real em dispositivos móveis. E como podemos ter algumas dezenas de produtos em um determinado quadro do feed da câmera do usuário, o alto desempenho por produto é fundamental. Novamente, nosso mecanismo de inferência interno provou seu verdadeiro valor aqui. O tempo de inferência é inferior a 10 ms por produto, o que significa que podemos fazer a detecção e a incorporação de uma prateleira média em bem menos de um segundo. O que temos agora é um sistema ágil sobre o qual nossa equipe de design pode criar uma experiência de usuário impressionante.

O processo de recuperação depende de uma conexão com a Internet, mas ao incorporar os produtos no dispositivo, eliminamos a necessidade de enviar imagens para o back-end. Só precisamos enviar cerca de 1Kb por produto, o que não é tão ruim assim.
Recuperação de produtos
O modelo de incorporação é onde a mágica acontece em nosso pipeline, mas a recuperação de back-end é igualmente importante em termos de desempenho e precisão. A parte do desempenho é fácil, pois há alguns excelentes bancos de dados vetoriais de código aberto disponíveis, mas a parte da precisão é complicada! Quanto mais imagens você tiver em seu sistema de recuperação, mais fácil será encontrar a imagem certa, especialmente se você tiver várias variações de imagens de produtos tiradas em diferentes condições de iluminação e sob diferentes ângulos.

Olhando para o futuro
O pipeline de reconhecimento de produtos que descrevemos abre um mundo de oportunidades para consumidores e empresas. Desde aumentar a experiência de compra na loja até melhorar a execução da loja, estamos animados para explorar todos os casos de uso em potencial dessa tecnologia e continuar a aprimorá-la.
Colaboradores: Luka Slibar, Matej Balun e Vito Pauletic