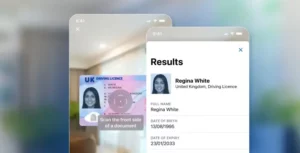
Extração de texto
A extração de texto é o processo de identificação e extração automática de informações relevantes de documentos de texto não estruturados, como e-mails, páginas da Web ou relatórios. Isso envolve a análise do texto e a identificação de pontos de dados específicos, como nomes, endereços, datas e números, bem como a extração de conteúdo significativo, como frases ou parágrafos.
A extração de texto normalmente emprega técnicas de processamento de linguagem natural (NLP), incluindo marcação de parte da fala, reconhecimento de entidade nomeada e análise de texto. Essas técnicas permitem que o sistema identifique e compreenda a estrutura e o contexto do texto, permitindo que ele extraia as informações desejadas com precisão.
A extração de texto tem inúmeras aplicações em vários setores. Ela pode ser utilizada para tarefas como mineração de dados, análise de sentimentos, categorização de conteúdo e recuperação de informações. Ao automatizar o processo de extração, as organizações podem economizar tempo e recursos e obter insights valiosos de grandes volumes de dados textuais.