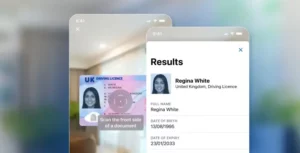
Correspondência difusa
A correspondência difusa é uma técnica usada na ciência da computação e no processamento de linguagem natural para encontrar correspondências ou semelhanças aproximadas entre duas sequências ou conjuntos de dados. É particularmente útil ao lidar com dados que podem conter erros, erros de digitação ou pequenas variações.
Os algoritmos de correspondência difusa calculam uma pontuação de similaridade entre duas cadeias de caracteres considerando fatores como similaridade de caracteres, distância de edição (o número de inserções, exclusões ou substituições necessárias para transformar uma cadeia de caracteres em outra), similaridade fonética ou outros recursos contextuais. Esses algoritmos fornecem uma medida da proximidade entre duas cadeias de caracteres, permitindo um grau de flexibilidade e tolerância para discrepâncias.
A correspondência difusa é comumente usada em aplicativos como corretores ortográficos, mecanismos de pesquisa, vinculação de registros e deduplicação de dados. Ela permite comparações eficientes e eficazes entre diversos conjuntos de dados, reduzindo o impacto de pequenas variações e aumentando as chances de encontrar correspondências relevantes.