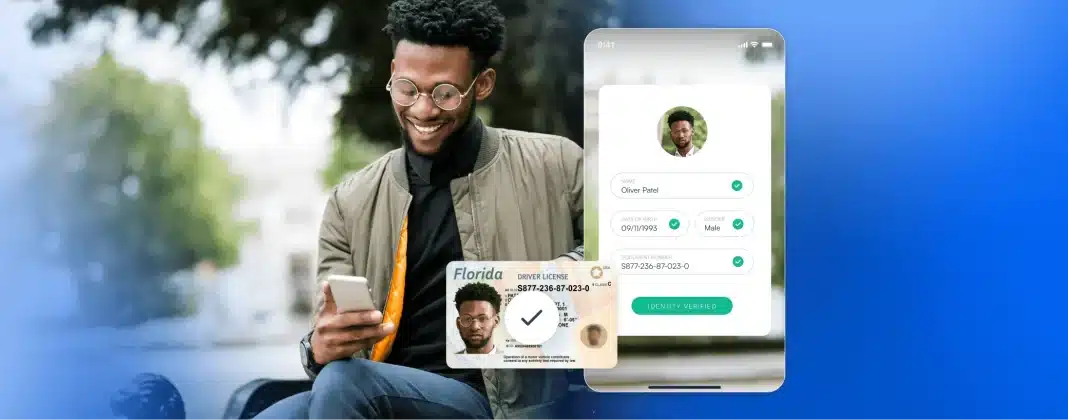
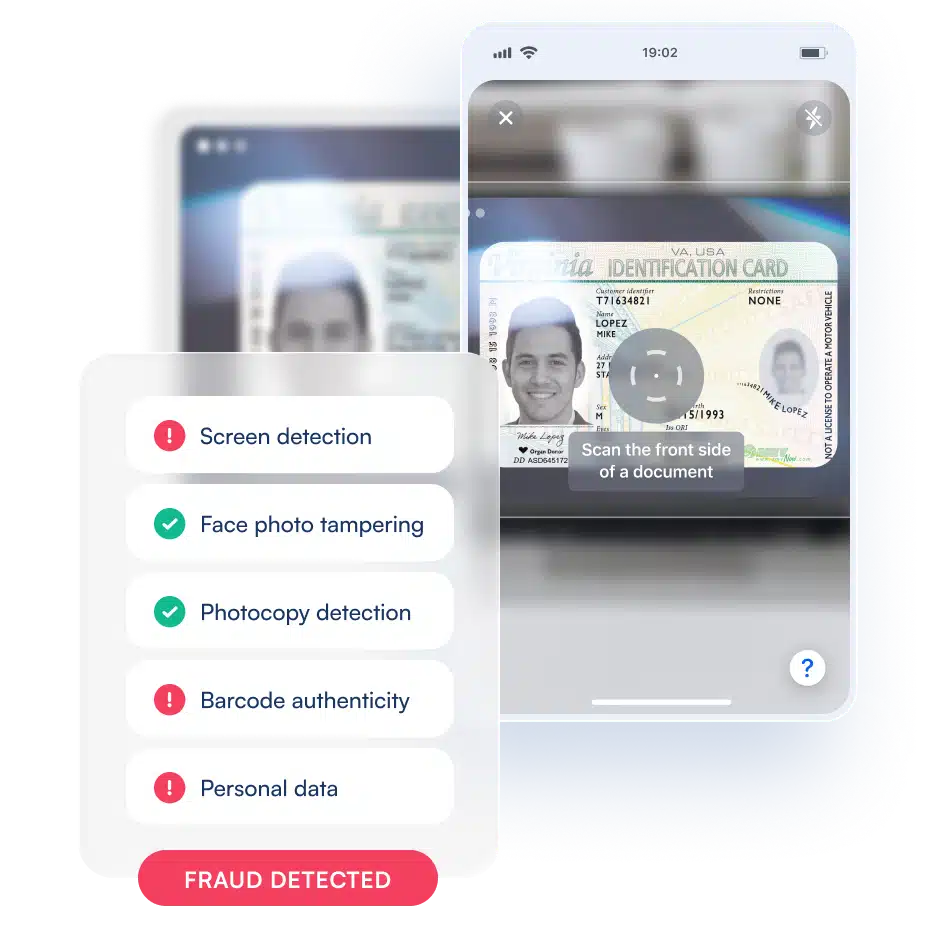
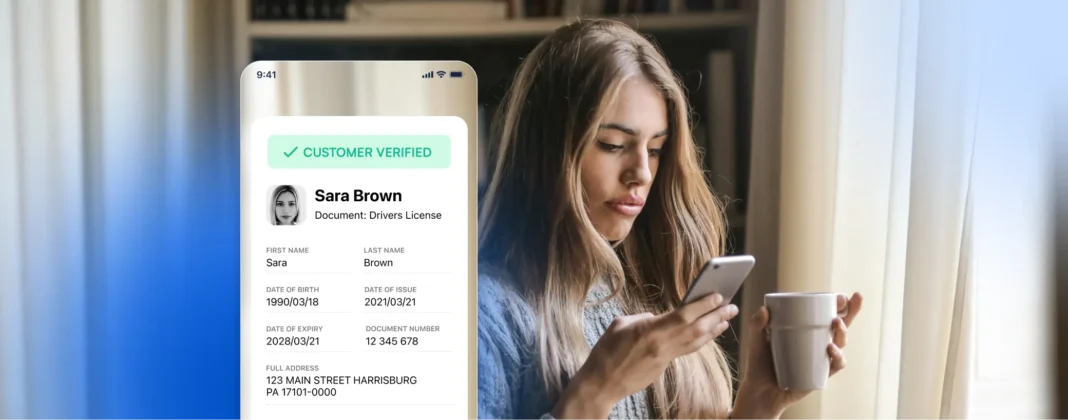
Construire BlinkID Capture : une interface utilisateur et une extraction de données encore meilleures

Chez Microblink, nous sommes fiers de nous considérer comme des experts en IA et en documents d’identité. Et pourtant, nous nous efforçons toujours de nous améliorer – à la fois pour nos partenaires clients et pour les utilisateurs finaux qui interagissent avec nos produits. À l’occasion de la sortie d’un nouveau produit BlinkID, nous avons discuté avec Luka Slibarnotre chef de produit BlinkID, et Daniel BalchevNous avons eu l’occasion d’échanger avec un ingénieur ML de l’équipe sur la façon dont nous envisageons de résoudre les problèmes d’identité numérique et sur la capture d’images qui est à la base de notre suite BlinkID. Les conversations ci-dessous ont été éditées et condensées pour plus de clarté.
Résoudre les problèmes d’identité numérique avec Luka Šlibar
J’ai occupé diverses fonctions chez Microblink depuis 2014. Je me suis d’abord concentré sur le développement commercial, puis j’ai évolué vers un rôle de gestion de produits pour nos initiatives d’IA, avant de devenir chef de produit pour les modules de capture et d’extraction de BlinkID.
Au fil des ans, Microblink a traité plus de 12 milliards de documents d’identité différents et, durant cette période, nous avons développé une perspective unique sur les nuances et les défis que ces documents contiennent. Les pièces d’identité varient en fonction de la géographie et de la personne, et changent régulièrement de format et de présentation. Qu’il s’agisse d’ouvrir un compte ou de transférer de l’argent, la plupart des expériences modernes et numériques que nous tenons pour acquises aujourd’hui dépendent de la numérisation et de l’authentification réussies de ces divers documents. C’est là que BlinkID intervient.
Lorsqu’il s’agit de résoudre les problèmes de nos clients et de relever le niveau de l’identité numérique, nous décomposons le processus en trois étapes clés : la capture, l’extraction et la vérification.
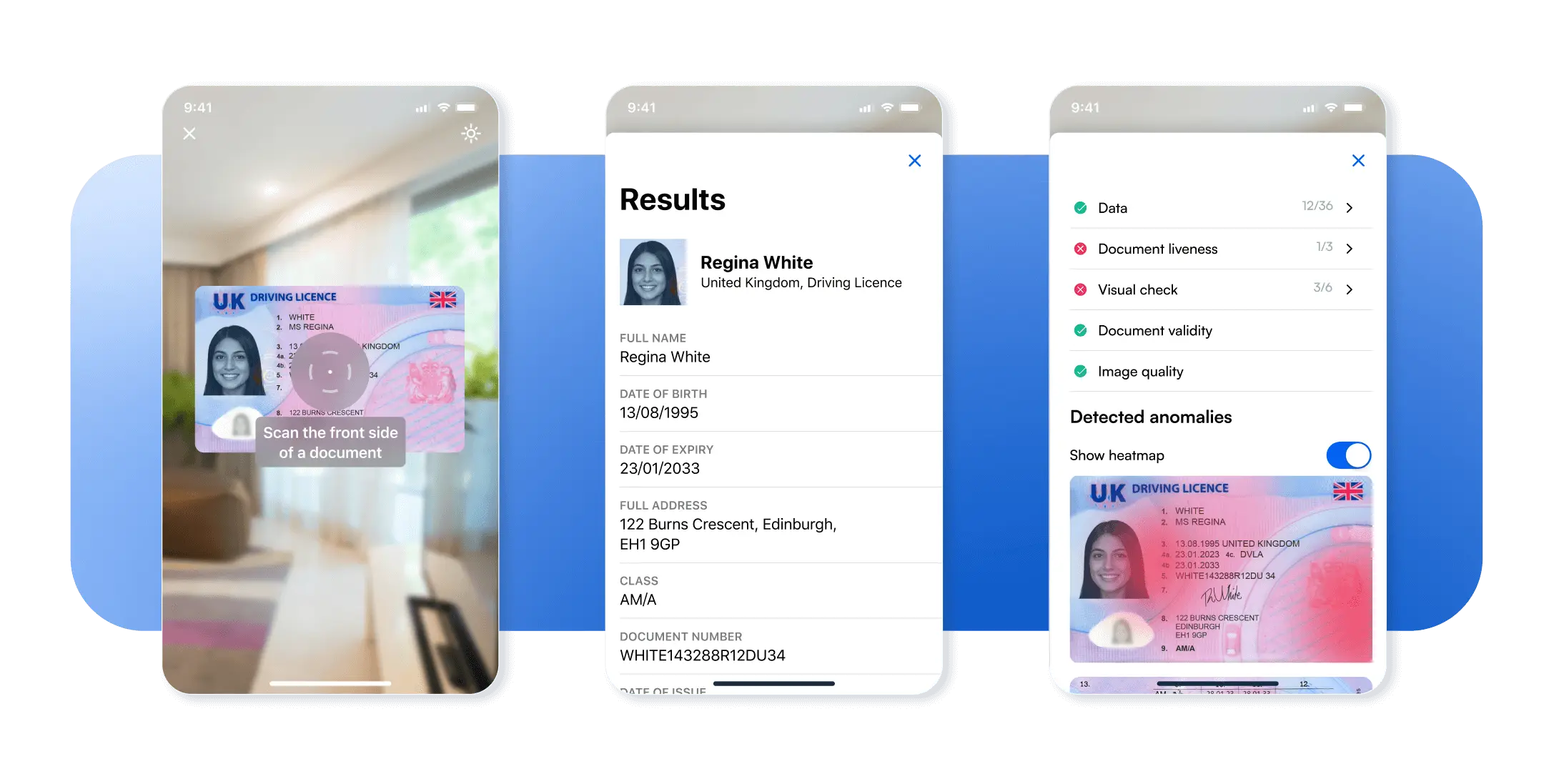
Une capture exceptionnelle des documents est essentielle au succès de la vérification en aval. Quels que soient les besoins spécifiques de l’entreprise, il est impossible de procéder à une vérification précise et fiable des documents d’identité sans une capture et une extraction d’images phénoménales. En d’autres termes, la capacité à vérifier la validité d’un document ou à le signaler comme potentiellement frauduleux dépend des données extraites, lesquelles dépendent de la qualité de la capture initiale. Si l’expérience de capture est maladroite, déroutante ou sujette à des erreurs, les utilisateurs risquent de l’abandonner complètement.
Microblink est traditionnellement connu pour le développement et la fourniture de SDK et d’API permettant d’automatiser les deux premières étapes du processus avec une rapidité et une précision inégalées dans l’industrie. Le traitement de BlinkID sur l’appareil offre une expérience utilisateur supérieure avec un retour d’information en temps réel (par exemple, « garder le document immobile » ou « reculer »), la sécurité des données et la capacité de prendre en charge des cas d’utilisation sans connexion Internet forte.
Malgré tous les progrès de la puissance de traitement des téléphones portables, celle-ci reste secondaire par rapport à la puissance de traitement d’un serveur complet. En outre, dans de nombreux secteurs très réglementés comme les services bancaires et financiers, auxquels notre technologie s’adresse, les images capturées sont de toute façon envoyées à un serveur en vue d’un traitement ultérieur.
Bien que nous ayons répondu aux besoins variés de nos clients grâce à des options d’intégration flexibles et à une large couverture des plates-formes, nous avons également vu une opportunité d’améliorer l’approche existante, en commençant par la capture d’images.
L’expérience de Microblink dans la création de produits hautement optimisés pour les appareils nous a particulièrement bien positionnés pour relever ce défi. En tant qu’équipe, nous savons comment développer des modèles ML légers et une expérience de capture d’image conviviale sans ajouter de taille inutile au SDK. Cela a également fait de ce projet un projet intéressant pour nos équipes interfonctionnelles.
Notre SDK de capture, qui vient d’être lancé, s’intègre dans les applications mobiles des clients pour permettre la fantastique expérience de capture de l’utilisateur pour laquelle notre produit phare BlinkID est connu, sans ajouter beaucoup à la taille globale de l’application. Il permet également un traitement et une extraction d’images plus puissants côté serveur, ce qui est essentiel pour notre vision à long terme qui consiste à fournir la meilleure solution globale de vérification des documents d’identité sur le marché.
Permettre une capture d’images encore plus intelligente, alimentée par le ML avec Daniel Balchev
J’ai rejoint Microblink à la fin de l’année 2022 en tant que l’un des trois premiers employés à Sofia, en Bulgarie, et je suis ravi de sortir le premier produit sur lequel j’ai travaillé avec l’équipe ! Grâce à notre richesse en modèles ML existants et à nos vastes données internes pour entraîner de nouveaux modèles, nous avons été en mesure de publier ce SDK en seulement 5 mois.
Il faut tout un village pour construire un produit comme celui-ci, et pour en arriver là, nous avons travaillé en étroite collaboration avec de nombreux ingénieurs ML, ingénieurs logiciels multiplateformes, concepteurs de produits et nos chefs de projet. Nous avons également discuté avec nos clients et nos collègues en contact direct avec la clientèle afin d’intégrer leurs commentaires et de nous assurer que nous construisons le bon produit. La version du SDK de capture d’images comporte de nombreuses fonctionnalités :
- Détection automatique des documents : Notre SDK est capable de détecter quand le document est visible et où il se trouve exactement, ce qui nous permet de déterminer si l’utilisateur tient un document trop près ou trop loin de la caméra ou sous un angle trop prononcé, en fournissant des instructions pour guider l’utilisateur vers une meilleure numérisation.

- Classification des types de documents : Notre nouveau SDK classe les documents en plusieurs catégories qui nous aident à déterminer leur rapport d’aspect attendu et si les documents sont recto ou recto-verso. Cette classification est particulièrement intéressante car elle nous permet d’adapter l’expérience de l’utilisateur et le flux de numérisation en fonction du document spécifique. En d’autres termes, si l’utilisateur présente une pièce d’identité, nous saurons qu’il faut demander le recto et le verso, au lieu du recto seulement pour un passeport.

- Détection du flou : détecte si le document est flou et attend que l’utilisateur prenne une meilleure photo, plus stable.
- Détection des reflets: Si des reflets couvrent le document, nous les détectons et demandons à l’utilisateur de déplacer le document de manière à ce qu’ils ne soient pas visibles.
- Détection de l’inclinaison: elle permet de savoir où se trouve le document dans l’image ou le cadre de la caméra et d’estimer si le document est incliné ou non. Bien que nous puissions prendre en charge les documents inclinés dans le cadre d’un traitement ultérieur, la transformation de ces images entraîne inévitablement une certaine distorsion de l’image transformée, ce qui est souvent indésirable lorsqu’il s’agit de vérifier si une image a été trafiquée. Il n’existe aucun moyen de corriger cette distorsion après la capture, de sorte que la seule solution consiste à fournir à l’utilisateur final des instructions en temps réel sur la manière de positionner correctement le document afin de supprimer l’inclinaison et de garantir la meilleure capture d’image possible.
- Occlusion de la main: Ce SDK réutilise les modèles de détection des mains de notre modèle de vérification pour détecter si la main d’un utilisateur recouvre une partie importante du document. (Ce qui est considéré comme « significatif » peut être configuré par le client). Cela permet d’éviter de capturer des images où un doigt recouvre une partie importante du document, par exemple.

- Estimation de la netteté : Nous capturons plusieurs images du document d’identité à partir du flux vidéo et les filtrons afin de sélectionner celle dont la qualité est la plus nette pour un traitement en aval le plus précis possible.
- Estimation des conditions d’éclairage : Nous pouvons détecter si l’utilisateur numérise dans une pièce sombre ou s’il y a trop de lumière et lui demander d’effectuer le changement nécessaire pour prendre une meilleure image.
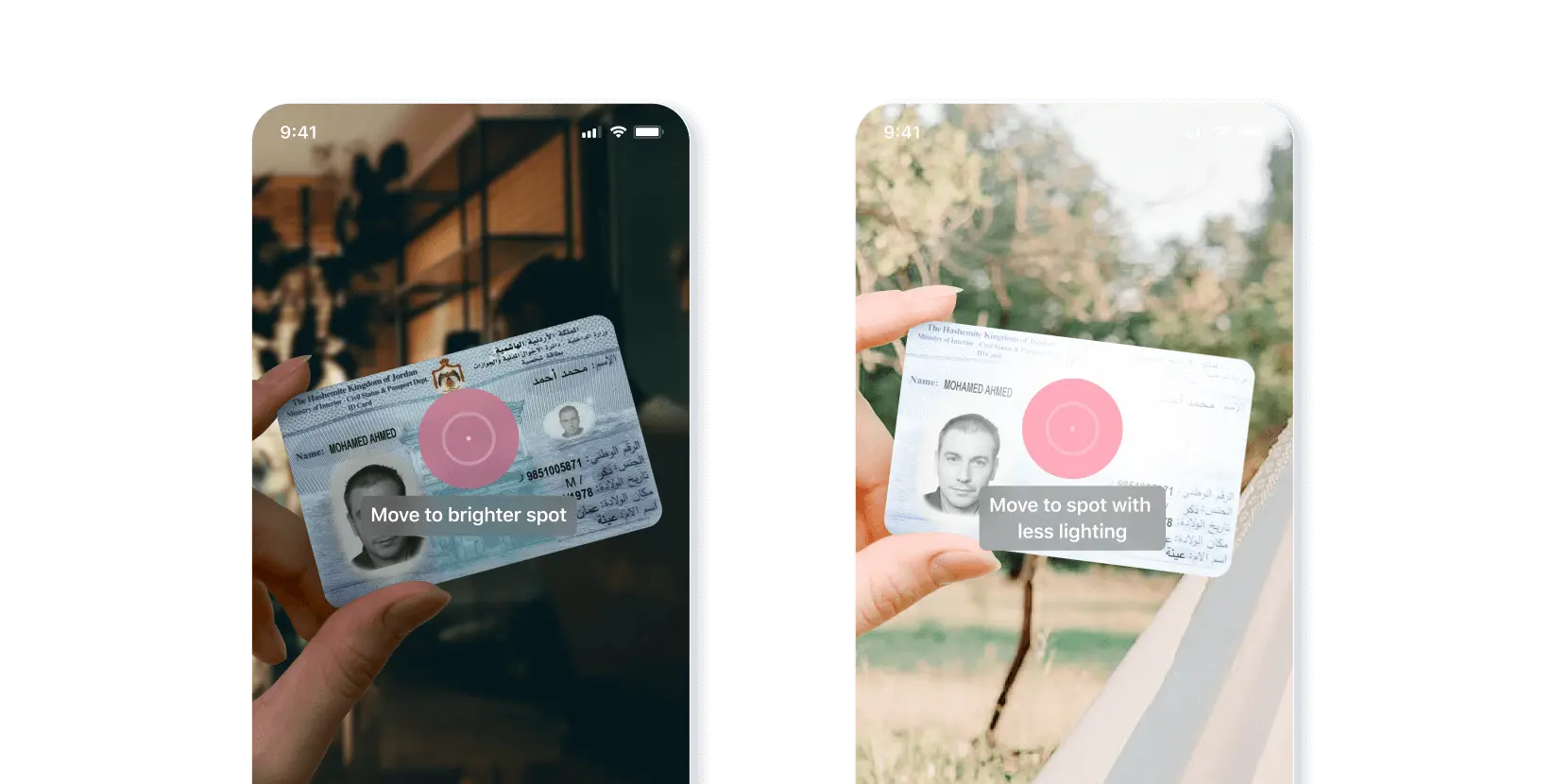
Il en résulte un retour d’information plus proactif et plus détaillé de la part de l’utilisateur, qui utilise la ML pour vérifier la qualité de l’image et garantir la meilleure numérisation possible dès la première fois, ce qui réduit la probabilité que l’utilisateur doive répéter le processus et permet une meilleure extraction.
Outre l’expérience de capture et la qualité d’image supérieures qu’il offre, notre SDK de capture autonome n’est pas limité à une liste de documents pris en charge. Il est donc conçu pour fonctionner avec toutes les cartes d’identité, tous les permis de conduire et tous les passeports de taille standard – aujourd’hui et à l’avenir. Si une nouvelle version de document est publiée, les clients n’ont pas besoin d’imposer une mise à jour à leurs utilisateurs, mais peuvent simplement mettre à jour le backend pour l’extraction.
Merci à Luka et Daniel d’avoir accepté de discuter avec nous !