Les magasins d’alimentation à travers les yeux de l’IA : construire une reconnaissance des produits en temps réel

Écrit par : Ivan Relić, ingénieur en chef de l’apprentissage automatique.
Chez Microblink, nous appliquons l’intelligence artificielle à des problèmes réels dans le but de faciliter la vie du plus grand nombre. Récemment, nos équipes de ML ont cherché des moyens d’utiliser la vision par ordinateur pour apporter le meilleur des achats en ligne dans les supermarchés du monde entier. Nous voulions permettre aux clients d’interagir avec les produits des supermarchés à partir de leur smartphone pour faire apparaître rapidement des éléments tels que :
- Revue des produits
- Offres de remboursement
- Informations sur les allergènes et valeurs nutritionnelles
- Tout ce qui peut améliorer leur expérience d’achat !
D’autre part, nous voulions que les fournisseurs, les détaillants et les marques de biens de consommation emballés (CPG) utilisent cette technologie pour organiser des promotions ciblées, orienter leur stratégie de prix et assurer le bon fonctionnement du magasin.

Nous ne sommes pas les premiers à travailler sur ce problème – Google a essayé de gagner du terrain avec une solution similaire – mais nous étions mieux placés pour l’aborder efficacement. Notre produit Shopper Intelligence capture déjà les données d’achat des tickets de caisse afin que les marques puissent créer des programmes de fidélisation basés sur des données, et que les acheteurs puissent en profiter. Au fil des ans, nous avons traité plus de 5 milliards d’achats uniques et créé un catalogue complet de produits de supermarché. Nous avons également mis au point un certain nombre de modèles ML conçus pour fonctionner efficacement sur des appareils mobiles. L’un de ces modèles, utilisé pour détecter les reçus, a également servi de référence pour détecter les produits en rayon.
Obtenir les données
Outre notre catalogue de produits, nous avons essayé d’utiliser un certain nombre d’ensembles de données open-source tels que SKU-110K pour obtenir des données de formation. Ces ensembles constituaient un bon point de départ pour la collecte de données, mais leur utilisation commerciale est interdite. Nous n’avions pas d’autre choix que de faire les choses nous-mêmes, et notre équipe s’est donc rendue dans les principaux magasins de détail du pays, prenant des images des rayons à distance ainsi que des images de produits individuels. Il leur a également été demandé de prendre une photo du code-barres de chaque produit, afin que nous puissions le relier à son CUP (code unique de produit) et obtenir un identifiant fiable pour notre recherche. En quelques mois, nous avons recueilli des millions de photos de magasins de détail dans tout le pays.

Ensuite, notre équipe d’annotation a passé en revue toutes ces images en essayant d’identifier les produits qui y figuraient. Nous disposons d’une équipe de 100 annotateurs. Pour accélérer leur travail, nous avons construit un modèle initial de pré-annotations qui nous a permis d’étiqueter des millions d’emballages de produits et des dizaines de milliers d’images d’étagères.
Nous étions maintenant prêts à commencer une véritable formation au mannequinat.
Détection de produits à partir d’un flux de caméras
La première chose à faire est de détecter les produits distincts lorsqu’ils se trouvent sur les étagères afin qu’ils puissent être classés par d’autres modèles plus tard dans le processus. Notre détecteur devait fonctionner en temps réel sur les appareils mobiles pour découper les images des produits lorsque l’utilisateur scrute le rayon de près et de loin.
Le modèle que nous avons formé met en place des boîtes de délimitation autour de chaque emballage de produit. À l’avenir, nous pourrions passer à une segmentation en polygones, car les biens de consommation ont tendance à être de toutes les formes et de toutes les tailles. Nous avons utilisé un seuil d’intersection et d’union relativement sévère de 0,7, ce qui nous a permis d’obtenir un score f1 de 92 %. Nous avons également réduit le temps d’inférence du modèle à moins de 100 ms sur l’iPhone 8 et les modèles supérieurs grâce à notre moteur d’inférence interne.
Le plus grand défi pour notre détecteur de produits à l’heure actuelle est la perspective de l’image. Lorsqu’une image est prise sous un certain angle, l’emballage d’un produit peut se retrouver avec une forme complètement différente et déformée. Pour résoudre ce problème, nous avons ajouté un modèle de détection des étagères. Nous pouvons utiliser l’étagère comme point de référence pour déformer rapidement les images et augmenter nos chances d’effectuer des détections précises.

Distinguer les produits
Une fois détectés, les produits doivent être classés dans leurs catégories respectives. Lorsque nous parlons de classes, nous parlons en fait de codes UPC – et il y en a BEAUCOUP. Non seulement il existe des millions de produits de supermarché, mais les marques adorent changer d’emballage quand elles en ont envie. Il ne s’agit donc pas d’un problème de classification comme les autres.
L’ampleur des classes potentielles nous a incités à essayer une approche différente, en utilisant un système d’intégration et d’extraction. L’idée est simple : convertir chaque photo de produit en un vecteur de caractéristiques, puis récupérer des vecteurs similaires dans la base de données. La représentation condensée des images de produits peut alors être comparée beaucoup plus rapidement et n’est pas sensible aux changements d’éblouissement et d’angle de balayage.
Nous disposons actuellement d’environ un million de produits indexés qui sont stockés et interrogés par rapport aux encastrements d’entrée à l’aide d’un algorithme k-NN, la valeur de sortie pour chaque paire allant de -1 à 1. Plus le produit en points est proche de 1, plus les produits sont similaires. Dans notre cas, la majorité des résultats supérieurs à 0,75 se sont avérés corrects, mais ce seuil est appelé à augmenter au fur et à mesure que nous développons notre index.
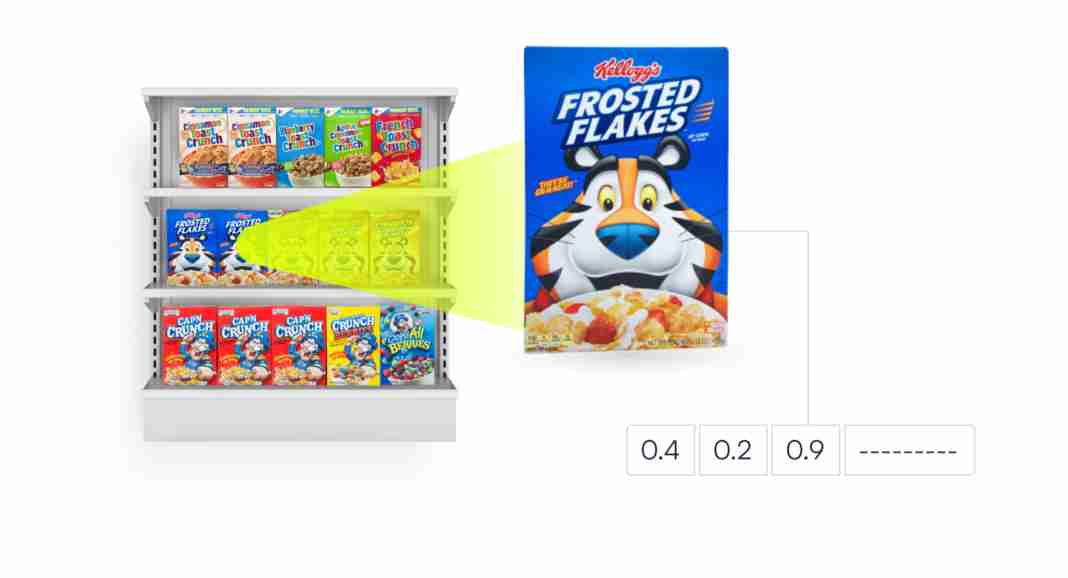
Nous avons expérimenté diverses architectures de modèles pour parvenir à la configuration qui fonctionne le mieux. Nous voulions que le modèle récupère les k vecteurs les plus similaires lorsqu’il reçoit une nouvelle image inédite d’un produit. Mais cela devient un véritable défi avec des différences fines telles que les tailles d’emballage et les saveurs, qui sont parfois difficiles à distinguer, même pour les humains.

Notre objectif était d’optimiser le taux de réussite au premier résultat de recherche, d’obtenir un rappel maximal et de faire en sorte que le modèle se généralise bien pour les produits qu’il n’a pas vus au cours de la formation. Le taux de réussite au premier résultat signifie qu’après avoir créé le vecteur d’intégration et l’avoir utilisé pour extraire, par exemple, une centaine de voisins les plus proches de la base de données, le vecteur le plus proche est en fait le bon produit. Il s’agit toutefois d’un scénario parfait, et le vecteur d’intégration peut encore avoir du mal à différencier de légères variations de produits. C’est pourquoi il est important d’avoir un rappel important pour que nos méthodes de reclassement aient plus de chances de choisir le vrai gagnant si ce n’est pas le premier.
Notre meilleur modèle actuel a un taux de réussite de 93% au premier résultat sur des exemples de produits non vus. Le taux de réussite pour les 10 plus proches voisins est de 98 %, ce qui signifie que le reclassement devrait donner des résultats précis dans la plupart des cas.
Tout comme le détecteur, ce modèle doit fonctionner en temps réel sur les appareils mobiles. Et comme nous pouvons avoir quelques douzaines de produits dans n’importe quelle image du flux de la caméra de l’utilisateur, une performance élevée par produit est primordiale. Là encore, notre moteur d’inférence interne a fait ses preuves. Le temps d’inférence est inférieur à 10 ms par produit, ce qui signifie que nous pouvons effectuer la détection et l’intégration d’une tablette moyenne en moins d’une seconde. Nous disposons maintenant d’un système rapide sur lequel notre équipe de conception peut construire une interface utilisateur étonnante.

Le processus de recherche dépend d’une connexion Internet, mais en intégrant les produits dans l’appareil, nous avons éliminé la nécessité d’envoyer des images au backend. Nous n’avons à envoyer qu’environ 1 Ko par produit, ce qui n’est pas si mal.
Recherche de produits
Le modèle de l’encodeur est l’endroit où la magie opère dans notre pipeline, mais la récupération du backend est tout aussi importante en termes de performance et de précision. La partie performance est facile car il existe d’excellentes bases de données vectorielles open source, mais la partie précision s’avère délicate ! Plus vous avez d’images dans votre système de recherche, plus il sera facile d’attraper la bonne, surtout si vous avez plusieurs variations d’images de produits prises dans différentes conditions d’éclairage et sous différents angles.

Perspectives d’avenir
Le pipeline de reconnaissance des produits que nous avons décrit ouvre un monde de possibilités pour les consommateurs comme pour les entreprises. De l’amélioration de l’expérience d’achat en magasin à l’amélioration de l’exécution en magasin, nous sommes impatients d’explorer tous les cas d’utilisation potentiels de cette technologie et de continuer à l’améliorer.
Collaborateurs : Luka Slibar, Matej Balun et Vito Pauletic