Disciplina de datos: La clave para liberar el verdadero poder de la IA

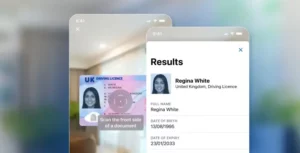
La naturaleza del comercio digital exige experiencias de entrada y salida del usuario fluidas y sencillas. Al mismo tiempo, la facilidad de uso no puede tener prioridad absoluta sobre la prevención del fraude. Equilibrar ambas se convierte en una tarea difícil para las empresas online, sobre todo teniendo en cuenta cómo los estafadores utilizan la IA para crear documentos de identidad sintéticos de aspecto muy auténtico, que pueden estar alterados de formas ligeras y difíciles de detectar con respecto a sus homólogos reales.
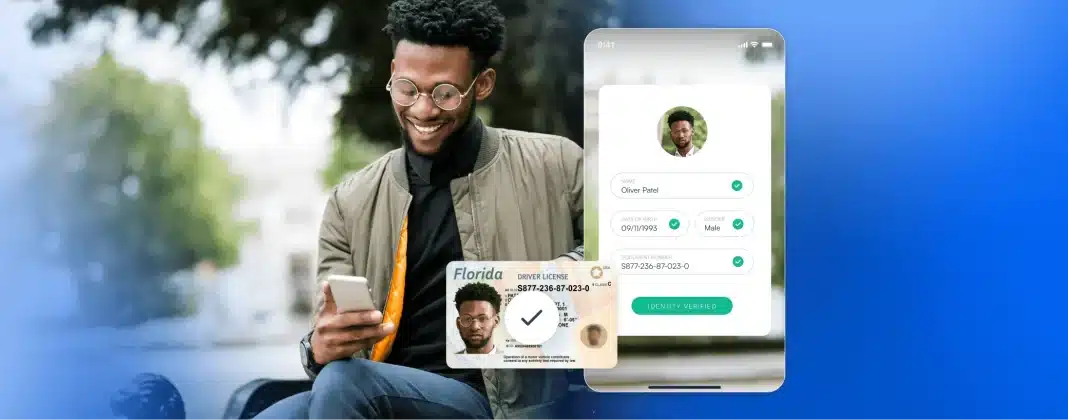
La verificación de la identidad digital y el procesamiento de pagos exigen no sólo velocidad, sino también precisión y seguridad. En Microblink, lo conseguimos aprovechando grandes cantidades de datos de alta calidad para entrenar nuestros modelos de aprendizaje automático. Pero los datos no sólo se recopilan, sino que se seleccionan cuidadosamente, se procesan y se perfeccionan continuamente para garantizar que nuestro BlinkCard y BlinkID soluciones sigan siendo punteras. Desde la adquisición hasta la anotación, cada paso de nuestra cadena de datos está diseñado para mejorar el rendimiento, detectar el fraude y respaldar una gama cada vez mayor de documentos globales.
Adquisición de datos – La base de la verificación de identidad y documentos
Un modelo sólo es tan bueno como los datos con los que se alimenta, por eso la adquisición de datos desempeña un papel vital en la IA. Se necesita un gran volumen de imágenes diversas de documentos como tarjetas de crédito, pasaportes y documentos de identidad para entrenar eficazmente los modelos de ML. Combinamos dos enfoques:
- Recogida de datos – Imágenes reales de documentos reales en el mundo real, basadas en versiones globales en constante evolución.
- Generación de datos sintéticos – Aprovechar la IA para realizar ingeniería inversa de muestras que sirvan a las necesidades de entrenamiento de modelos a medida.
La importancia del cumplimiento
Cuando se manejan tantos datos, es importante mantener el cumplimiento de todas las leyes de privacidad del usuario, como la GDPR.
Todos los usuarios tienen también la opción de excluirse de la recopilación de datos y de que sus datos se eliminen en cualquier momento. Aplicamos prácticas estrictas de minimización de datos, de modo que sólo utilizamos los datos necesarios para la formación de modelos y la mejora de productos.
Nuestro marco de cumplimiento incluye auditorías y evaluaciones periódicas para garantizar que nuestros procesos de tratamiento de datos se ajustan a los cambiantes requisitos normativos. También colaboramos estrechamente con expertos jurídicos y de seguridad para mantener las mejores prácticas en la gestión de datos. Al dar prioridad a la privacidad y la seguridad, no sólo cumplimos las obligaciones legales, sino que también reforzamos la confianza con nuestros usuarios y socios.
Procesamiento de datos: Limpieza y estructuración para modelos ML
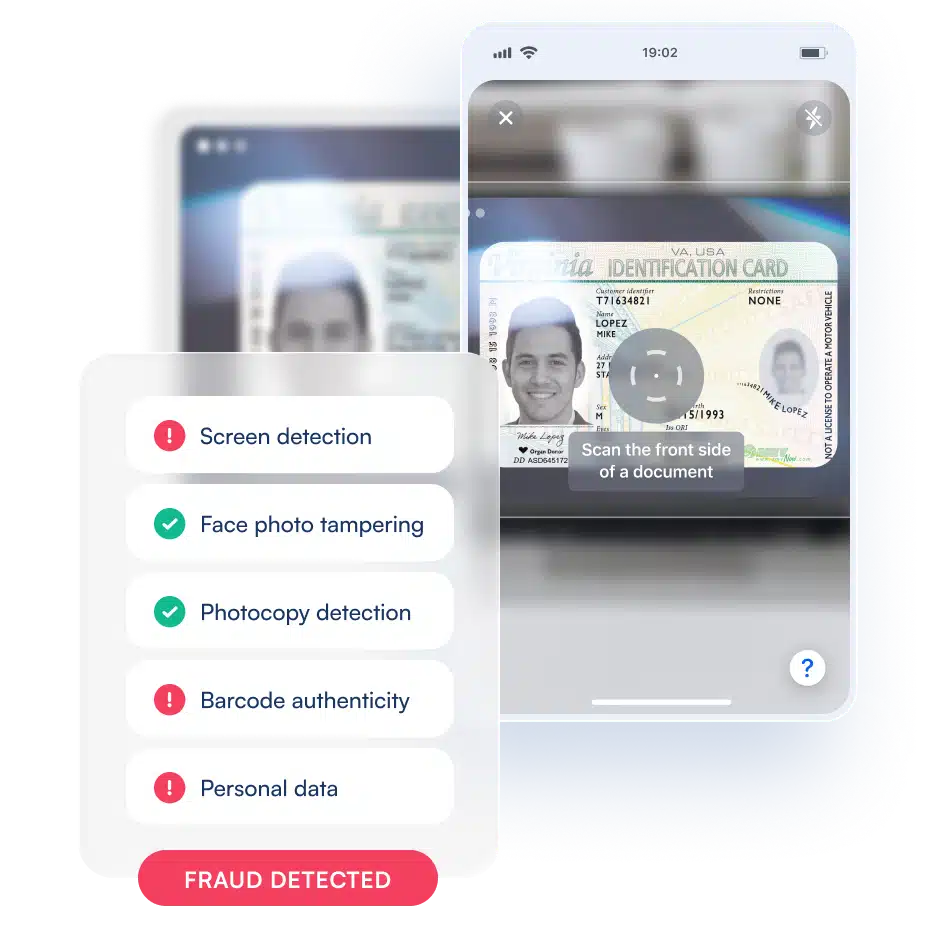
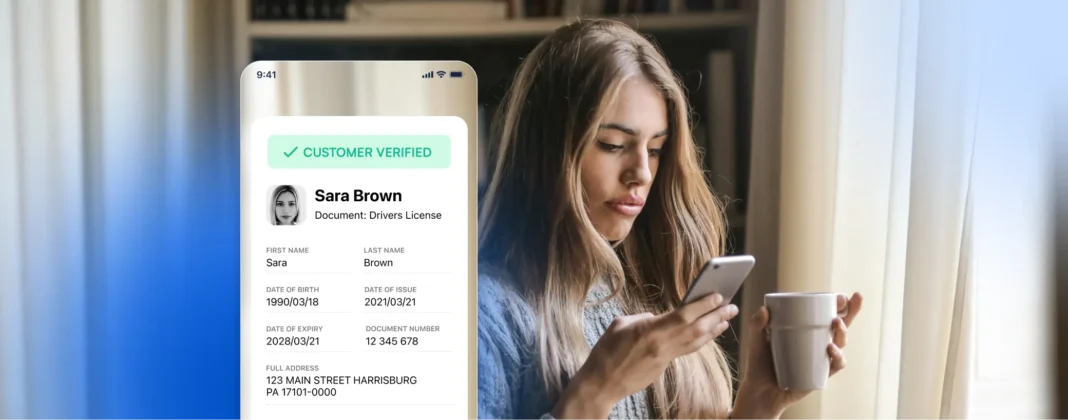
Los datos brutos rara vez son utilizables en su forma original. Antes de que puedan utilizarse para el entrenamiento, nuestros datos se someten a múltiples pasos de procesamiento. El preprocesamiento garantiza que los datos de baja calidad o irrelevantes se filtren para mantener una alta precisión. A continuación se procede a la categorización de los datos, donde un equipo especializado analiza cada documento, identificando los elementos clave y estructurando los datos correctamente. A continuación se lleva a cabo la anotación, en la que expertos etiquetan campos específicos de los documentos, como nombres, direcciones y fotos, para entrenar los modelos ML con precisión. La detección de fraudes desempeña un papel fundamental en nuestro proceso, ya que nuestros expertos en documentos los examinan cuidadosamente para identificar los manipulados o falsos, garantizando que nuestros modelos puedan detectar actividades fraudulentas en aplicaciones del mundo real.
Además de estos pasos básicos, Microblink emplea metodologías adicionales para refinar y estructurar aún más los datos. Se realiza una clasificación previa al procesamiento para eliminar las imágenes inservibles y detectar objetos de interés en las imágenes. También determinamos la utilidad y las categorías generales de todos los documentos e imágenes que se capturan. La categorización de los datos garantiza que se reconozcan las variaciones regionales y los cambios de formato, mejorando la adaptabilidad del modelo.
El factor humano
Cabe señalar además que nuestro equipo de anotadores es totalmente interno, algo que muchos otros proveedores -que subcontratan estas tareas- no pueden decir. Se trata de expertos que pueden detectar incluso alteraciones o diferencias sutiles en documentos sintéticos fraudulentos y registrar esos datos, que luego se introducen en nuestros modelos ML y se utilizan para detectar con mayor precisión indicios de fraude.
Las técnicas de anotación exhaustivas, como el uso de recuadros delimitadores para resaltar los campos críticos de los documentos y la transcripción del texto a formatos estructurados, mejoran la eficacia del entrenamiento de ML. El reconocimiento de patrones de fraude permite a nuestro sistema cruzar referencias con patrones fraudulentos conocidos, reforzando nuestros mecanismos de prevención del fraude. Por último, las actualizaciones continuas de los modelos garantizan que los datos procesados y validados se integren en nuestro canal de entrenamiento de ML, manteniendo nuestras soluciones a la vanguardia de la evolución de las normas documentales.
Aprendizaje automático basado en datos: Entrenamiento de la próxima generación de modelos
Nuestro equipo de ML construye y refina continuamente modelos para admitir nuevos tipos de documentos y mejorar la precisión. Este proceso implica analizar nuevas versiones de documentos para identificar cambios en el formato, las características de seguridad y la colocación del texto. Cuando no se dispone de muestras del mundo real, generamos documentos sintéticos aleatorios para ayudar al entrenamiento del modelo. Una vez que los datos están anotados y estructurados, se utilizan en el proceso de entrenamiento y despliegue de modelos, lo que permite a nuestros modelos de ML aprender a reconocer, extraer y verificar datos de documentos de forma eficaz.
La ventaja de Microblink: Calidad, experiencia y escalabilidad
Lo que nos diferencia es nuestra profunda experiencia en el campo y nuestras capacidades internas. A diferencia de los proveedores externos, controlamos toda la cadena de datos, desde la adquisición hasta la anotación, garantizando la coherencia, precisión y seguridad de los datos. Esto nos permite iterar con rapidez, adaptarnos a nuevos tipos de documentos y escalar con eficacia, manteniendo al mismo tiempo los más altos niveles de calidad. A medida que sigamos innovando, los datos seguirán estando en el centro de nuestra tecnología. Ya se trate de mejorar la detección del fraude, ampliar el soporte global de documentos o automatizar el procesamiento de datos, nuestro compromiso de aprovechar los datos de forma responsable garantiza que BlinkCard y BlinkID ofrezcan las mejores experiencias de su clase tanto a las empresas como a los usuarios. Si quieres saber más sobre cómo Microblink puede ayudar a tu empresa a combatir el fraude y deleitar a los clientes, ponte en contacto con nosotros hoy mismo.