Las tiendas de comestibles a través de los ojos de la IA: Construyendo el reconocimiento de productos en tiempo real

Escrito por: Ivan Relić, Ingeniero Jefe de Aprendizaje Automático
En Microblink, aplicamos la inteligencia artificial a problemas del mundo real con el objetivo de facilitar la vida al mayor número posible de personas. Recientemente, nuestros equipos de ML han estado estudiando formas de utilizar la visión por ordenador para llevar lo mejor de las compras online a los supermercados de todo el mundo. Queríamos permitir que los compradores interactuaran con los productos del supermercado desde su smartphone para sacar rápidamente a la superficie cosas como:
- Reseñas de productos
- Ofertas de devolución
- Información sobre alérgenos y valores nutricionales
- Cualquier otra cosa que mejore su experiencia de compra.
Por otro lado, queríamos que los proveedores, los minoristas y las marcas de bienes de consumo envasados (BPC) utilizaran esta tecnología para realizar promociones específicas, orientar su estrategia de precios y mantener el buen funcionamiento de la tienda.

No somos los primeros en trabajar en este problema -Google ha intentado ganar terreno con una solución similar -, pero estábamos mejor situados para abordarlo con eficacia. Nuestro producto Shopper Intelligence ya captura los datos de compra de los recibos de los comercios para que las marcas puedan crear -y los compradores rentabilizar- programas de fidelización basados en datos. A lo largo de los años, hemos procesado más de 5.000 millones de compras únicas y hemos creado un catálogo completo de productos de supermercado. También hemos creado una serie de modelos ML diseñados para funcionar eficazmente en dispositivos móviles. Uno de esos modelos, utilizado para detectar recibos, también sirvió de base para detectar productos en las estanterías.
Obtener los datos
Aparte de nuestro catálogo de productos, hemos intentado utilizar varios conjuntos de datos de código abierto, como SKU-110K, para obtener datos de entrenamiento. Eran un buen punto de partida para la recopilación de datos, pero su uso comercial está prohibido. No nos quedó más remedio que hacer las cosas nosotros mismos, así que nuestro equipo fue a las principales tiendas de todo el país, tomando imágenes de las estanterías desde lejos, así como imágenes de productos individuales. También se les pidió que hicieran una foto del código de barras de cada producto, para que pudiéramos conectarlo con su UPC (Código Único de Producto) y obtener un identificador fiable para nuestra recuperación. En sólo unos meses, recopilamos millones de fotos de tiendas de todo el país.

A continuación, nuestro equipo de anotación revisó todas estas imágenes intentando identificar los productos que aparecían en ellas. Contamos con un equipo de 100 anotadores. Para acelerar su flujo de trabajo, creamos un modelo inicial de pre-anotaciones que nos permitió etiquetar millones de envases de productos y decenas de miles de imágenes de estanterías.
Ahora estábamos preparados para empezar a hacer un entrenamiento de modelos adecuado.
Detectar productos de un flujo de cámara
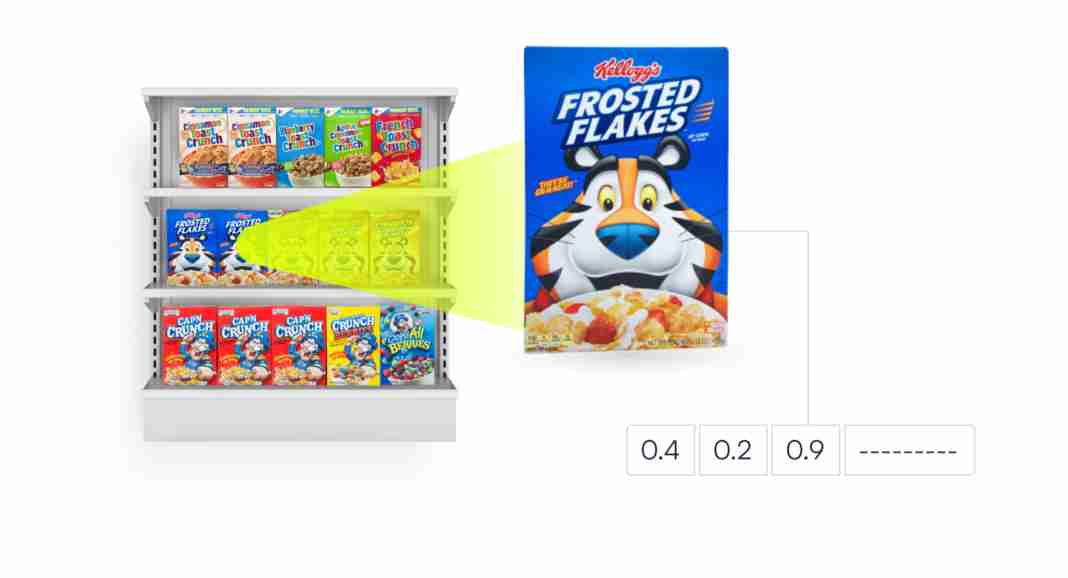
Lo primero que tenemos que hacer es detectar productos distintos mientras están en las estanterías, para que puedan ser clasificados por otros modelos más adelante en el proceso. Nuestro detector tenía que funcionar en tiempo real en dispositivos móviles para recortar las imágenes de los productos tanto cuando el usuario escanea la estantería de cerca como de lejos.
El modelo que entrenamos pone recuadros delimitadores alrededor de cada envase de producto individual. En el futuro, podríamos cambiar a la segmentación poligonal, ya que los bienes de consumo suelen tener todas las formas y tamaños. Utilizamos un umbral de intersección sobre unión relativamente duro, de 0,7, y aún así conseguimos una puntuación f1 del 92%. También redujimos el tiempo de inferencia del modelo a menos de 100 ms en el iPhone 8 y superiores, gracias a nuestro motor de inferencia interno.
El mayor reto para nuestro detector de productos en este momento es la perspectiva de la imagen. Cuando una imagen se toma desde un ángulo, el envase de un producto puede acabar teniendo una forma completamente diferente y distorsionada. Para resolver este problema, hemos añadido a la mezcla un modelo de detección de estanterías. Podemos utilizar la estantería como punto de referencia para desenfocar rápidamente las imágenes y aumentar nuestras posibilidades de hacer detecciones precisas.

Diferenciar los productos
Una vez detectados, los productos deben clasificarse en sus respectivas clases. Cuando decimos clases, en realidad nos referimos a los UPC, y hay MUCHOS. No sólo hay millones de productos de supermercado, sino que a las marcas les encanta cambiar sus envases cuando les da la gana. Definitivamente, no es el problema de clasificación de todos los días.
La enorme escala de clases potenciales nos empujó a probar un enfoque diferente, utilizando un sistema de incrustación y recuperación. La idea es sencilla: convertir cada cultivo de producto en un vector de características y luego recuperar vectores similares de la base de datos. La representación condensada de las imágenes de los productos puede compararse mucho más rápidamente y no es sensible a los cambios de brillo y ángulo de escaneado.
Actualmente tenemos alrededor de un millón de productos indexados que se almacenan y consultan contra las incrustaciones de entrada mediante un algoritmo k-NN, con el valor de salida de cada par oscilando entre -1 y 1. Cuanto más se acerque el producto punto a 1, más similares serán los productos. En nuestro caso, la mayoría de las recuperaciones por encima de 0,75 han resultado correctas, pero este umbral aumentará a medida que sigamos ampliando nuestro índice.
Experimentamos con diversas arquitecturas del modelo para llegar a la configuración que mejor funcionaba. Queríamos que el modelo recuperara los k vectores más similares cuando se le diera una nueva imagen no vista de un producto. Pero esto se convierte en un verdadero reto con diferencias finas, como los tamaños y sabores de los envases, que a veces son difíciles de distinguir incluso para los humanos.

Nuestro objetivo era optimizar la tasa de aciertos en el primer resultado de recuperación, conseguir la máxima recuperación y que el modelo generalizara bien los productos que no había visto durante el entrenamiento. La tasa de acierto en la primera recuperación significa que, después de crear el vector de incrustación y utilizarlo para recuperar, digamos, cien vecinos más cercanos de la base de datos, el vector más cercano es realmente el producto correcto. Sin embargo, éste es el escenario perfecto, y el incrustador puede seguir teniendo problemas para diferenciar entre ligeras variaciones del producto. Por eso es importante tener una fuerte recuperación, para que nuestros métodos de reordenación tengan más posibilidades de elegir al verdadero ganador en caso de que no sea el primero.
Nuestro mejor modelo actual tiene una tasa de acierto del 93% en el primer resultado sobre ejemplos de productos no vistos. El porcentaje de aciertos en los 10 vecinos más próximos es del 98%, lo que significa que la reclasificación debería dar resultados precisos en la mayoría de los casos.
Al igual que el detector, este modelo debe funcionar en tiempo real en los dispositivos móviles. Y como podríamos tener un par de docenas de productos en cualquier fotograma de la cámara del usuario, es primordial un alto rendimiento por producto. Una vez más, nuestro motor de inferencia interno demostró aquí su verdadera valía. El tiempo de inferencia es inferior a 10 ms por producto, lo que significa que podemos realizar la detección e incrustación de una estantería media en menos de un segundo. Ahora tenemos un sistema ágil sobre el que nuestro equipo de diseño puede crear una experiencia de usuario asombrosa.

El proceso de recuperación depende de una conexión a Internet, pero al incrustar los productos en el dispositivo, eliminamos la necesidad de enviar imágenes al backend. Sólo tenemos que enviar aproximadamente 1 Kb por producto, lo que en realidad no está tan mal.
Recuperación de productos
El modelo de incrustación es donde se produce la magia en nuestro proceso, pero la recuperación del backend es igualmente importante en términos de rendimiento y precisión. La parte del rendimiento es fácil, ya que hay disponibles algunas bases de datos vectoriales de código abierto estupendas, pero la parte de la precisión resulta complicada. Cuantas más imágenes tengas en tu sistema de recuperación, más fácil será dar con la correcta, especialmente si puedes tener múltiples variaciones de imágenes de productos tomadas en diferentes condiciones de iluminación y bajo diferentes ángulos.

De cara al futuro
El canal de reconocimiento de productos que hemos esbozado abre un mundo de oportunidades tanto para los consumidores como para las empresas. Desde aumentar la experiencia de compra en la tienda hasta mejorar su ejecución, nos entusiasma explorar todos los posibles casos de uso de esta tecnología y seguir mejorándola.
Colaboradores: Luka Slibar, Matej Balun y Vito Pauletic